AI技術革新が描く製造業の未来と日本の現在地
- テクノロジー
- コンサルティング
- 製造業
- ものづくり

目次

Podcast『製造業進化論-技術とデジタルと経営と-』
オーツー・パートナーズ制作Podcast番組『製造業進化論-技術とデジタルと経営と-』にて、本コラムを執筆した武田秀樹が『AIで描く製造業の未来』をテーマにトーク。MCは当社取締役の勝見靖英が務めます。
1 新技術導入の不安解消へ
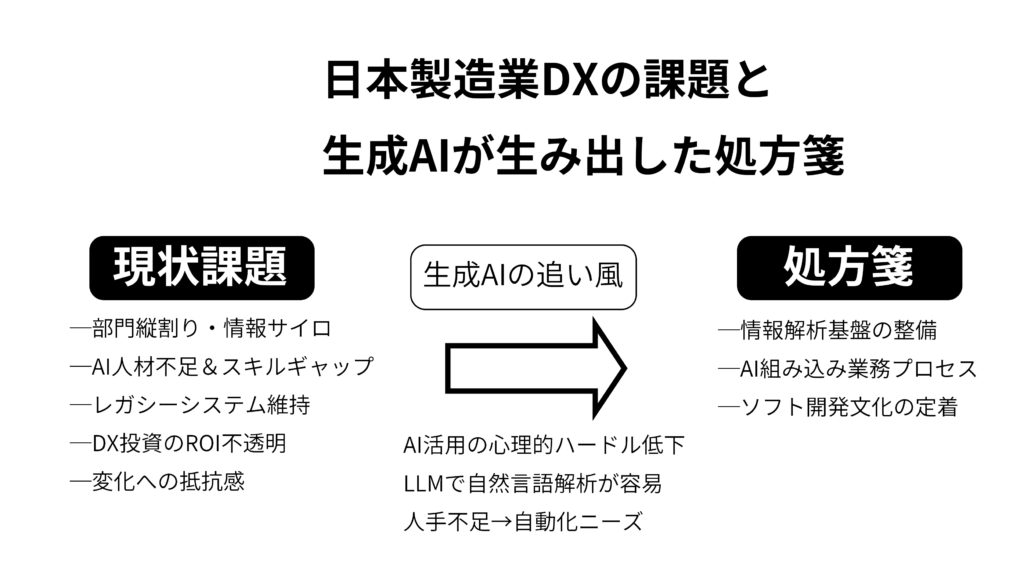
デジタル化の足踏みが続き、現場の進度はいまだに遅い。経産省『2025年版ものづくり白書』によれば、個社単位のデジタル化・効率化は一定の成果を示す一方で、全体最適や新製品・サービス創出による事業機会拡大まで踏み込む企業は依然として少ない。必要性と現実のギャップを肌で感じている製造業関係者も多い。
日本の製造業がDX推進で遅れている背景には複数の構造的課題がある。部門間の縦割り体制と情報のサイロ化が全体最適な意思決定を阻害し、AI・データ人材不足やレガシーシステム維持が重い負荷となっている。DX投資のROIが不透明な中、新技術や働き方の変化に対する抵抗感も依然として残る。なお2025年版白書は、成果創出には経営層のコミットメントとサプライチェーン横断のデータ連携が不可欠と強調している。
このような課題は新しいようで古い課題ではないか。筆者は2000年代前半、製造業に対し特許文書・技術データに自然言語処理(当時はテキストマイニングと称された)を適用する解析を提案していた。その経験を踏まえると、当時から新技術導入への抵抗感は強かった。人手よりはるかに短い工数で有用なインサイトを抽出できるという確信もあり、自然言語処理活用の意義は揺らがなかったが、導入が進まないことへの歯がゆさは拭えなかった。
その間に世界の状況は大きく変わった。2010年代の第三次AIブームやクラウド普及を経て、さらにここ数年の生成AIの進歩により、自然言語による指示でコンピュータを制御できる領域に達した。事前学習済みモデルにより初期投資が縮小し、PoC(概念実証)も容易になった。導入ハードルは大きく低下した。だがこれは表層の話だ。意思決定層に残る深層的な心理的抵抗と組織慣性は根強く、20年前にも実感した「新技術導入への不安」は形を変えて現在も続く。その結果、生成AIを戦略レベルで活用し全社最適まで昇華した企業は限られるという状況につながっている。
本連載では、マルチモーダルAI、AIエージェント、LLM(大規模言語モデル)など生成AI技術が、製造業のスマートファクトリー、ナレッジマネジメント、製品開発をどのように変革し得るかを国内外の事例を交えて検討する。鍵となるのは情報解析基盤の整備、AIを組み込んだ業務プロセス改善、ソフトウェア開発による価値創造を企業文化として定着させることである。日本の製造業が生成AI時代の好機を最大限に生かす処方を提示する。これは最後のチャンスになるかもしれない。
2 マルチモーダル化
ここ数年、AIは大きく発達したと感じる声が多い。その要因は、自然言語対話と画像生成などマルチモーダル処理の実現にある。マルチモーダルとは複数のモダリティ(情報表現形式)を横断的に扱う技術を指す。従来、機械学習モデルはテキストは単語列、画像は画素列、音声は波形として個別に前処理する必要があり、異なるモダリティを統合的に解析することは容易ではなかった。しかし、近年の大規模事前学習によりその壁が崩れつつある。DeepSeek Janus ProやLLaVAなどのVision-Languageモデルは言語理解能力を画像解析に応用し、文脈内学習で多くの問題を解決可能とした。Stable Diffusionに代表される拡散モデルは、テキストからの画像生成を「適用可能な」技術として各分野に導入を促進している。スマートファクトリー用に設計された高度なビジョン・ランゲージ・モデルである、MaViLaのような研究もこの分野の好例であろう。
スマートファクトリー分野は、センサーデータや画像といった複数のモーダルを扱う品質管理が2010年代からいち早く行われてきた領域でもあるが、生成AIの技術取り込みはどうなっているのだろう。欧州における先行例は、Boschのヒルデスハイム工場の例である。不良品画像合成で検査AIの学習期間を6ヶ月短縮し、年間6桁ユーロの生産性向上を達成した。学習データを増やすことにより、希少欠陥検出精度の向上を可能にした点が特筆される。
しかしまだ事例は少なく、新技術のスマートファクトリーへの取り込みは端緒についたところである。
新しい技術の推進という点で興味深い事例がある。2025年、BMWレーゲンスブルク工場では、生成AI「GenAI4Q」が車両仕様と生産ログを統合解析し、1日1,400台の検査カタログを個別最適化する仕組みを実用化した。
GenAI4Qプロジェクトで協業したDatagon AI(現Manex AI)は、BMW出身の創業者Nathan Gruberらによって設立された企業である。「BMW在籍中に必要だったソリューションが見つからなかったため、自ら開発した」背景を持つ同社は、BMW、Stellantis、Audiなど欧州主要製造業の信頼を獲得し、2025年6月には800万ユーロの資金調達を完了している。現場出身の創業者により、実用的な技術開発が実現している。
また、同工場では2019年にWEF Lighthouse認定される前から、多くのデータ解析が進められており、生成AIのためのデータ活用基盤が整備されてきたと想像できる。
この事例から学べることは、技術の完全成熟を待つのではなく、段階的投資により導入を早め、学習データも蓄積し、次の技術導入の土台とする戦略的アプローチが有効であるということだ。特に重要なのは、現場課題を深く理解した技術パートナーとの協業体制である。
ドイツは競業避止補償制度により、元勤務先との協業が維持しやすい背景もある。
日本でも退職者との関係を「外部パートナー」として明確に捉え直すことから始めてはどうか。元従業員が設立したスタートアップとの業務委託契約や共同開発契約、社内起業制度の拡充などは、既存の法制度内でも十分実現可能だ。重要なのは、組織の境界を越えた継続的学習ネットワークの構築である。今後到来するマルチモーダルAI時代の競争優位は、技術そのものではなく、不確実性下での継続的学習能力にある。
3 効果可視化、人も生かす
大規模言語モデルの進化が加速する中、AIエンジニアは自身の技術が陳腐化する恐怖を抱いている。プロンプトエンジニアリングでも複雑な技法から「シンプルな指示」重視への流れが生まれているように、技術の価値は絶えず変動する。
しかし現在、AIに複雑な仕事を任せるには依然として高度な技術が必要だ。特にAIエージェント技術は、プランニング(計画)、リフレクション(反省)、メモリー(記憶)など、人間の思考プロセスを体系化したかのような要素で構成される。CursorやClaude CodeなどのAI開発ツールをみれば、エージェント技術の最も洗練された姿とその強力な効果がわかる。
この技術は製造業の生産工程にも新たな可能性をもたらそうとしている。 独シーメンスは5月、デトロイトのAUTOMATE 2025で「Industrial AI Agents」を発表した。複数の専門エージェントが連携し、設計から保守まで一貫した工程を自動化。生産性を最大50%向上させる潜在力があると発表した。
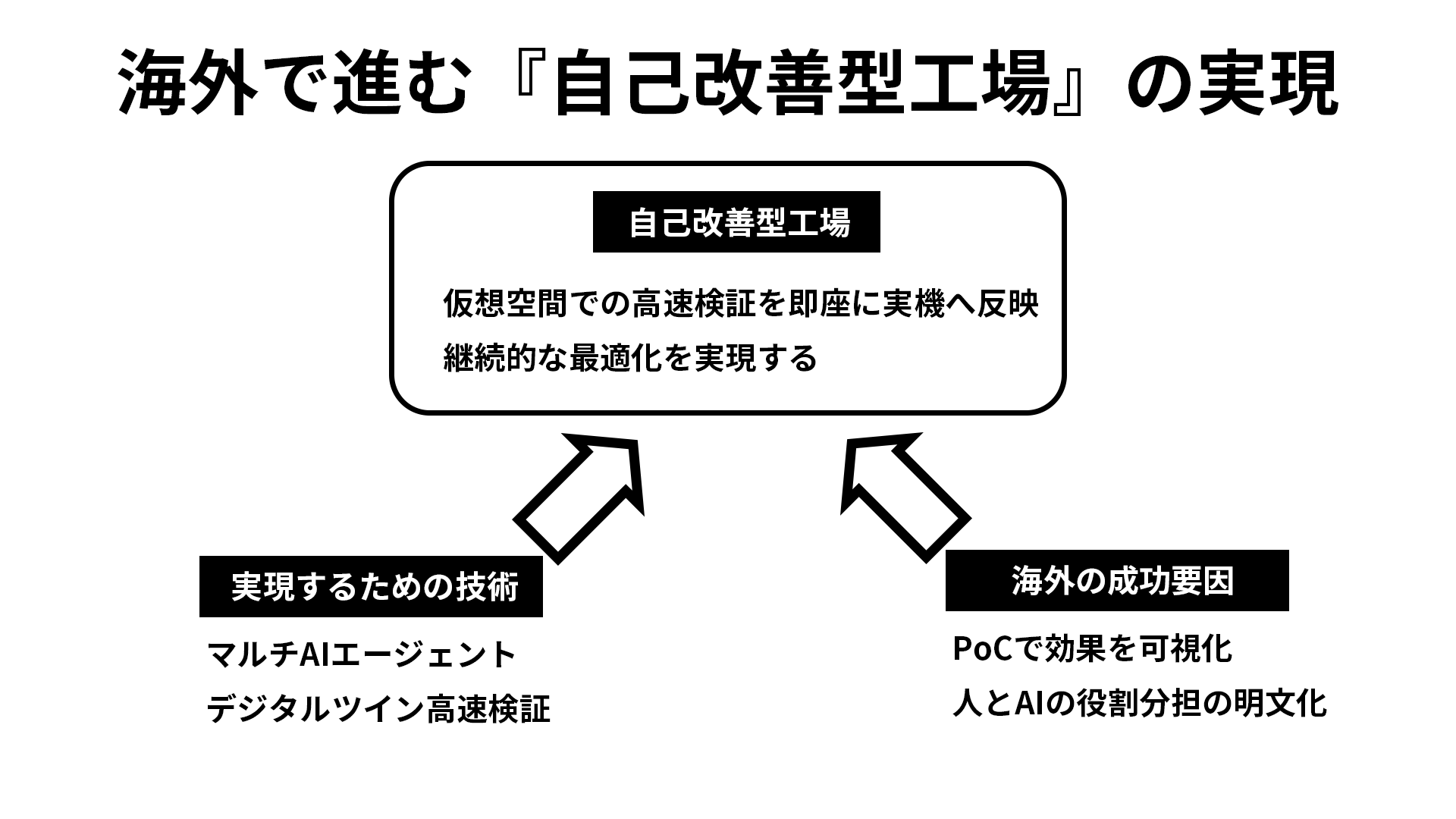
台湾の鴻海精密工業(フォックスコン)は、NVIDIA Omniverseを活用した「Fii Omniverse Digital Twin」を運用中だ。工場全体を仮想空間に再現し、熱流体解析を従来比150倍の速度で実行、AIエージェントによる監視・レイアウト検証をリアルタイムで行う。年間エネルギー消費30%以上の削減も期待している。
これらの事例は、AIエージェント技術の多様な応用を示している。今後、フォックスコンのようなマルチエージェントとデジタルツインの融合による「自己改善型工場」が、仮想空間での高速検証を実機へ即座に反映する新たな製造モデルとなりそうだ。
一方、国内企業は雇用減への懸念、初期投資の負担、技術人材不足によりAI導入を躊躇している。意思決定者は投資効果を数値化できず、従業員は役割変化に不安を抱く。これが導入停滞の要因だ。
海外のAIエージェント普及要因は2つ。PoCで効果を即時可視化し投資判断を下げること、人とAIの役割分担を明文化し雇用不安を解消することだ。 技術提供側のシーメンスは最大50%の生産性向上を提示し段階投資を促進。ユーザー側のフォックスコンは仮想工場で30%超の省エネを期待し、エンジニアがロボット訓練に参加する協働モデルを構築。
日本企業が踏み出すべき次の一歩は明確だ。AIを業務に組み込んだ上で、業務プロセスを「計画―実行―反省―学習」のループで再設計し、効果を定量的に測定すること。そして人とAIの協働による新たな働き方を示すことである。 数値に裏付けられた投資効果と、人を活かす物語。この両輪が揃ったとき、自律型AIエージェントは単なる省力化ツールを超え、製造現場の意思決定プロセスを革新する原動力となる。
4 LLMを用いた知識管理
近年の大規模言語モデル(LLM)は、速い推論から深い論理的思考へと進化した。ChatGPTのo1シリーズに代表されるように、言語モデル自体が段階的に推論することで、より正確な回答を導けるようになった。この進化により、ハルシネーション(誤情報生成)が大幅に減少し、汎用的な判断能力が向上している。
この技術革新を支えるのが、プロセス監督による強化学習だ。従来の「正解」ではなく「考え方のプロセス」を評価して学習させる手法で、ChatGPTのo1シリーズで本格採用され、他の主要モデルでも研究・実験が進んでいる。また推論時計算量スケーリングにより、小型モデルでも適切な計算量を割り当てることで、特定のタスクにおいて大型モデルを上回る性能を実現できることが実証されている。
このように進化を続けるLLMだが、ナレッジ管理はLLMと相性が良い領域だ。言語解釈力の高いLLMは様々なナレッジを横断的に処理できる。LLMの活用を明記している事案は少ないものの、生成AIのナレッジ管理領域での活用事例をみていこう。
欧州エアバスは昨年5月、生成AIとLLM活用の全社的な進展を公表し、標準作業指示書などの技術文書を自然言語で検索できる社内チャットボットを実証中だ。現場技術者は「どのトルクスパナを使うべきか」といった質問に瞬時に回答を得られ、社内ワーキンググループ発足から1年足らずで600件超の業務ユースケースが特定された。
また提供側の例としては、米ハネウェルが今年2月、生成AI搭載の「Intelligent Assistant」でKPI逸脱要因を自然言語で解析し、根本原因を対話形式で提示するシステムを発表している。
一方、日本の製造業では、先進的な企業がある中でもLLM活用に課題を抱える。機密性の高い技術情報を扱う特性上、外部クラウドサービス利用に慎重な企業が少なくない。実際の現場では、こうしたセキュリティ懸念により概念実証(PoC)段階にも到達できない企業や、PoCをスタートしたものの遅々として進まない企業が多いのが現状だ。
しかし、適切なセキュリティ設計により安全なLLM活用は可能だ。機密度に応じて技術文書を分類し、機密性の低い文書から電子化を開始する。次にセキュリティを考慮したクラウド環境での小規模LLM検索システムを構築し、「技術情報探索時間の8割削減」といった具体的な目標を設定して効果を実証する。
アクセス権限管理、暗号化通信、監査ログの整備によりデータ流出リスクは段階的に解消できる。重要なのは、過去に蓄積された技術資産を活用しなければ競争力向上の機会を逸することだ。
経営層がデータ活用の価値を正しく理解し、適切なリスク管理のもとで前進すれば、深い推論能力を備えたAIは工場現場でも継続学習するパートナーへと進化する。製造業のデジタル変革において、LLMを活用した知識管理は避けて通れない道筋となっている。
5 異なるデータの統合 部門を超えた基盤構築が重要
異なるデータの統合は古くて新しい課題だ。
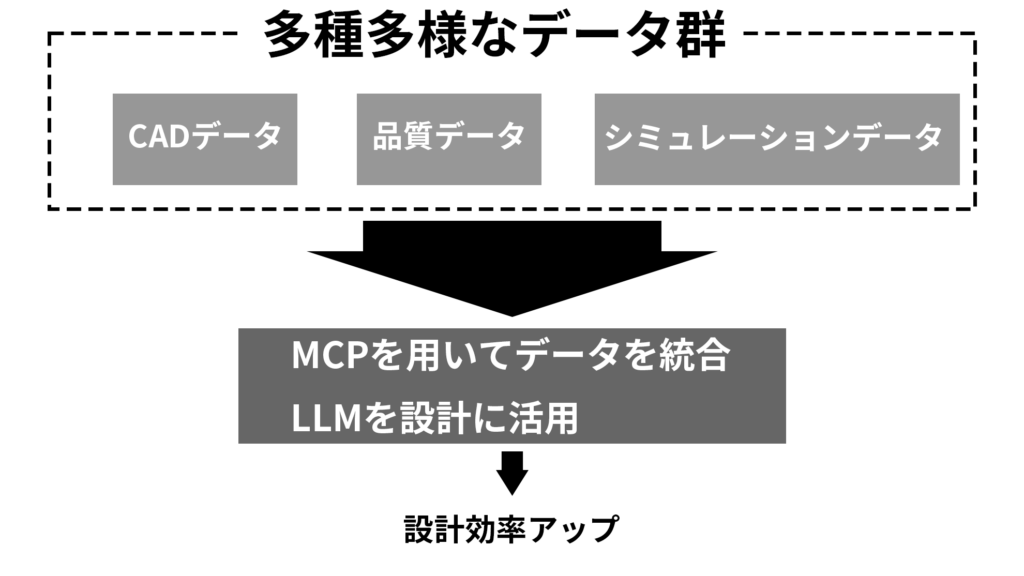
大規模言語モデル(LLM)がテキストを柔軟に、強力に処理できることが分かると、様々なデータをLLMで処理したいと考えるのが人情だ。ところが、異なる種類のデータをLLMで処理させるためには、種類毎に入力データを一つ一つ個別に設定し、統合する必要があり、骨が折れる。
そんな中、2024年11月にアンソロピックが公開した「AIのUSB-C」こと Model Context Protocol(MCP)は、OpenAI(2025年3月)とグーグル(同4月)が相次いで採用を表明し、わずか5ヶ月でデータ統合の業界標準として急速に定着した。MCPにより異なるシステム間のデータ統合が簡素化され、「とりあえずデータを入力して試す」環境が整いつつある。
このデータ統合の課題は、製造業の設計分野でも同様に存在する。実際、データ統合に成功した企業は劇的な成果を上げている。
電力管理大手イートンは生成AIを設計工程に導入し、照明器具の設計期間を従来の 16 週間から 2 週間へと 87 %短縮した。過去製品の設計・品質・シミュレーションデータを学習させたAIが数千件の設計反復を数分で実行し、最適案上位 5 件を自動抽出する仕組みを構築した。さらに、液体―空気熱交換器では重量を 80 %削減し、高速ギアの開発では設計時間を 65 %短縮する成果を上げている。
同社のウイヨサ・アブソムワン上級技術マネージャーは2024年11月の業界カンファレンスで「従来の設計プロセスを数カ月から数分に短縮することを目指している」と語り、生成AI導入により新製品投資効果を倍増させる計画を示した。
イートンの成功要因は、異なる種類のデータを統合してAIに学習させた点である。過去の製品データとシミュレーション結果という別種類の情報を組み合わせてAIアルゴリズムを訓練することで、従来の設計プロセスを革新した。
一方、多くの日本企業では部門ごとのサイロ化により、AI活用の前提となる統合データ基盤が整備されていない事が多い。従来のデータ統合基盤をゼロから構築するには極めて多くの時間とコストがかかる。
ここでMCPの価値が浮き彫りになる。
既存システムをそのまま活用しながら標準化されたプロトコルにより、大規模なシステム再構築を避けつつデータ統合を実現できる。
特に開発期間が受注機会を左右する産業では、AI活用の有無が決定的な競争格差を生む可能性がある。日本企業にとって重要なのは、MCPのようなデータ統合技術を活用して部門を超えた統合基盤を段階的に構築することである。
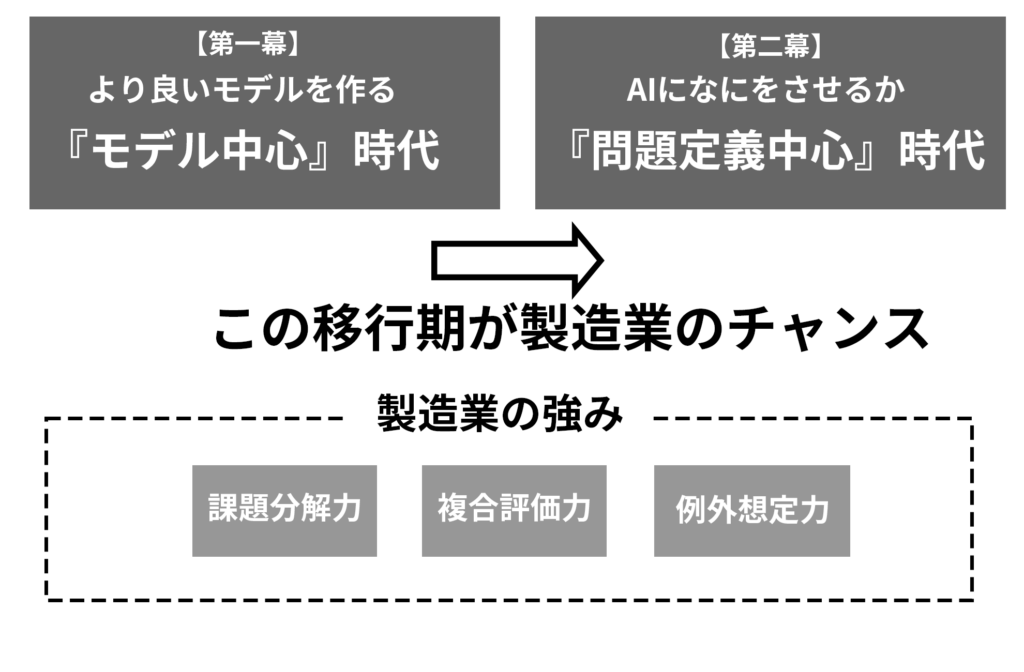
6 AI発展は「第2幕」─日本企業に最大の勝機
総務省の2025年版情報通信白書によれば、企業での生成AI利用率は日本55.2%に対し、米国90.6%、中国95.8%、ドイツ90.3%となっている。この差は確かに大きく、日本が遅れていることは事実だ。しかし重要なのは、海外企業も技術の完全な定着には至っておらず、日本企業にもまだ追いつくチャンスがあるということだ。
本連載を振り返ると、海外企業の生成AI活用も面で見れば、決して完璧ではないことが分かる。開発期間の大幅短縮、検査プロセスの最適化、設計工程の効率化といった劇的な成果は確かに注目に値するが、これらは各技術分野における限定的な成功例に過ぎない。さらに、報告される事例を詳細に検証すると、必ずしも最新の大規模言語モデルを利用しているかどうかは定かでなく、もっと広く生成AIという技術を利用しているのでは、と思う例もしばしばあった。
一方、日本企業でもパナソニック コネクトの社内AIアシスタント「ConnectAI」は1日5000回利用され、その実績を基にパナソニックグループ全体への展開を進めるなど、利用が広がっている。
本連載では、生成AIの中核技術である大規模言語モデル(LLM)の歴史に類を見ない進化スピードを追ってきた。しかし、この急激な技術進化は、ある種の歩留まりの予兆でもある。AI研究者Shunyu Yaoが指摘する通り、大規模言語モデルの基本的な学習手法が確立され、汎用的なモデルが十分に強力になったため、同じモデルでも課題設定や評価方法の違いによって成果が大きく変わる状況になった。新しい技術的課題を設定しても、既存の手法ですぐに解決されてしまう状況が生まれている。
AI発展は「第二幕」に入った。第一幕は「より良いAIモデルを作る」モデル中心の時代だった。しかし第二幕は「AIに何をさせるか/どう評価するかを再定義する」問題定義中心の時代である。 この構造変化が製造業にとって大きなチャンスとなる。製造業は複雑なプロジェクトを部品単位に精緻に分解してきた経験により、AIタスクを適切な判断単位に分割して指示できる素養を有する。品質・コスト・納期という複合的な評価指標での最適化経験は、AIの制約条件下でのタスク設計に直結する。さらに、品質保証で培った例外的な状況を事前に想定する経験は、AIが失敗しやすい状況を予測した問題設計力の源泉となる。
LLMによる本質的な変化は、自然言語でコンピュータが操作できるようになったことだ。現場の技術者が直接AIを活用できる環境が整った。最終的には内製化していくべきだが、その過程でドメインを知るパートナーとの協働が不可欠だ。 重要なのは単なる技術習得ではなく、ソフトウェア開発文化の定着である。従来の製造業は「一発で完璧に作る」文化だったが、生成AI時代には「作って→試して→直して」の高速反復が求められる。できない理由は全て正しい。だからこそ、それを延々と議論するより「制約の中で何ができるか」を実装で示す文化こそが価値創造の源泉となる。
これには段階的アプローチが有効だ。まずは外部パートナーと自社エンジニアがペアを組み、具体的なプロジェクトを通じて知識移転を図る。次に混成チームで複雑な課題に取り組み、最終的に自社エンジニアが主導権を握る。この過程で「完璧な計画」より「動くプロトタイプ」を重視する文化を育てることが肝要だ。
第二幕では、現場の「暗黙課題」をAIが扱える評価タスクに翻訳し、「現場の価値」が明確に出る評価プロトコルを定義することが求められる。汎用LLMを「現場文脈に適応」させることで、個別解決力を育てる実装→フィードバックループの構築が成功の鍵となる。
過度な恐れを捨て、小さく始めて大きく育てることだ。評価の再設計と現場起点の実装が、次の産業的ブレークスルーを生む。日本の製造業にとって、これは主役になれる最大のチャンスである。